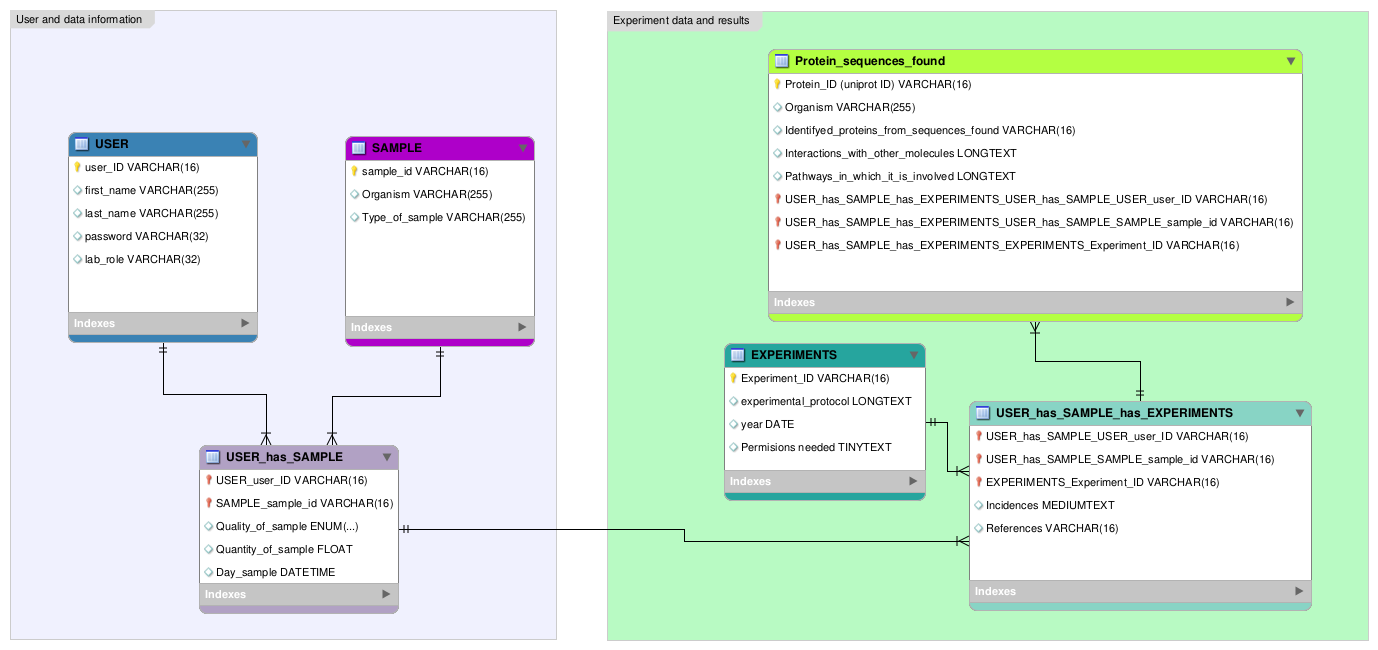
A data model for a series of proteomics analysis
Following we will see a data model for a series of proteomics. We have to imagine that we want to create an application in which the researchers from a laboratory can upload their experimental results from proteomics protocols. Therefore, with a login they well have access to their current samples and their experiments history.
In this instance, we have taken into account that the samples are those that we can obtain from an individual (being a human, another animal, among others).
The users are the researchers, and since we can collect several samples from a specific individual, one sample can belong to several users, as well as one user can have several samples.
But what matters to us are the outcomes of those samples. As a result, we have a sample for each user (the one that they are using) that will adhere to an experimental design (a protocol), and the researcher will obtain data from this.